Mit Explainable AI (XAI) sollen KI-Systeme transparent, nachvollziehbar und überprüfbar gemacht werden. in dem Zusammenhang kommt dem Reasoning eine besondere Rolle zu:
„Unter Reasoning versteht man den Prozess, bei dem ein KI-System seine internen Schlussfolgerungen sichtbar macht, etwa in Form logisch strukturierter Argumentationsketten oder textuell formulierter Teilschritte (sogenannter Chains-of-Thought)“ (Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen).
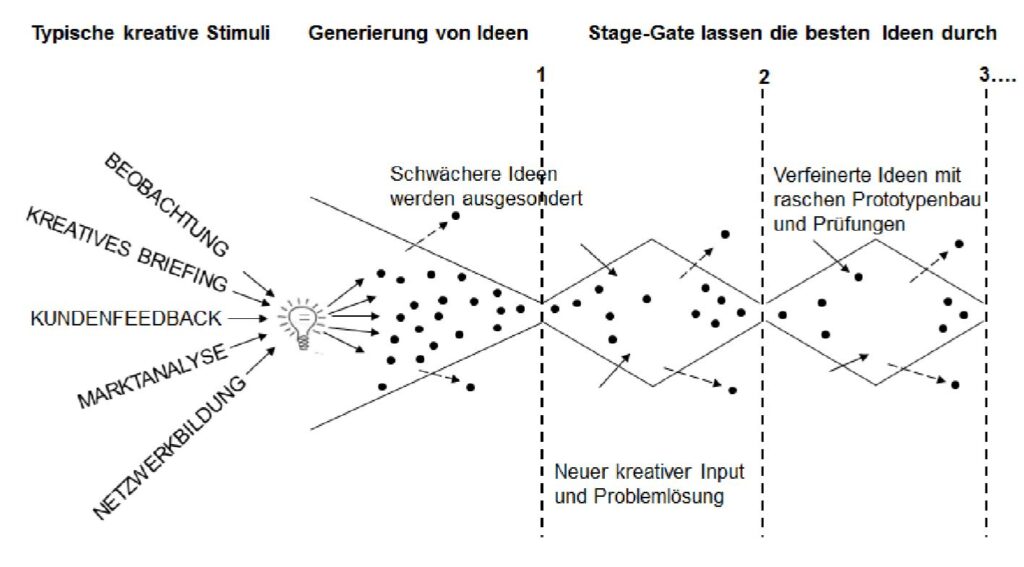
XAI und Reasoning ermöglichen es gerade Kleinen und Mittleren Unternehmen die jeweiligen Prozessschritte zumindest teilweise nachzuvollziehen.
„Transparenz allein genügt nicht, wenn die Systeme nicht kontrolliert, erweiterbar und datensouverän betrieben werden können“ (ebd.).
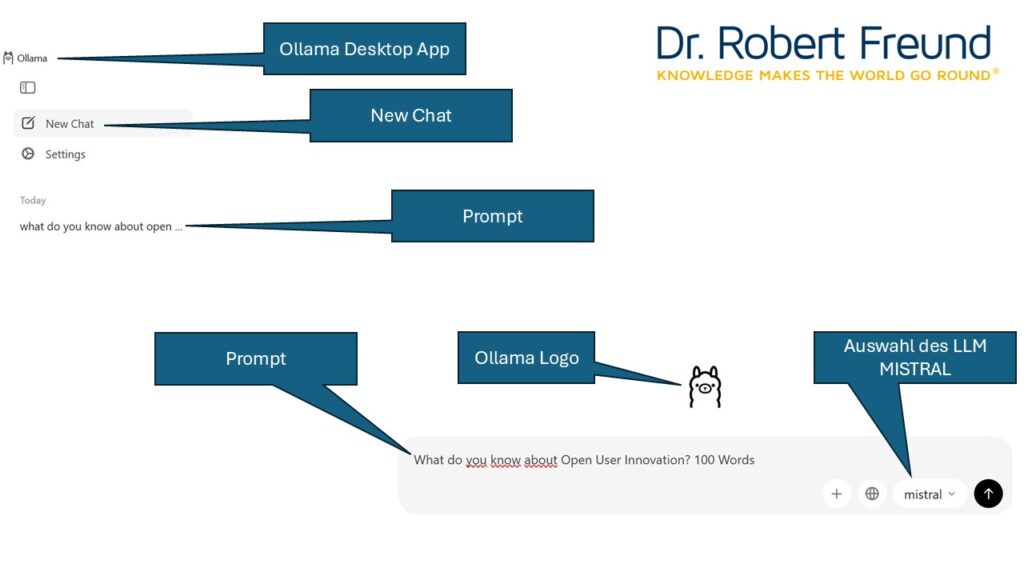
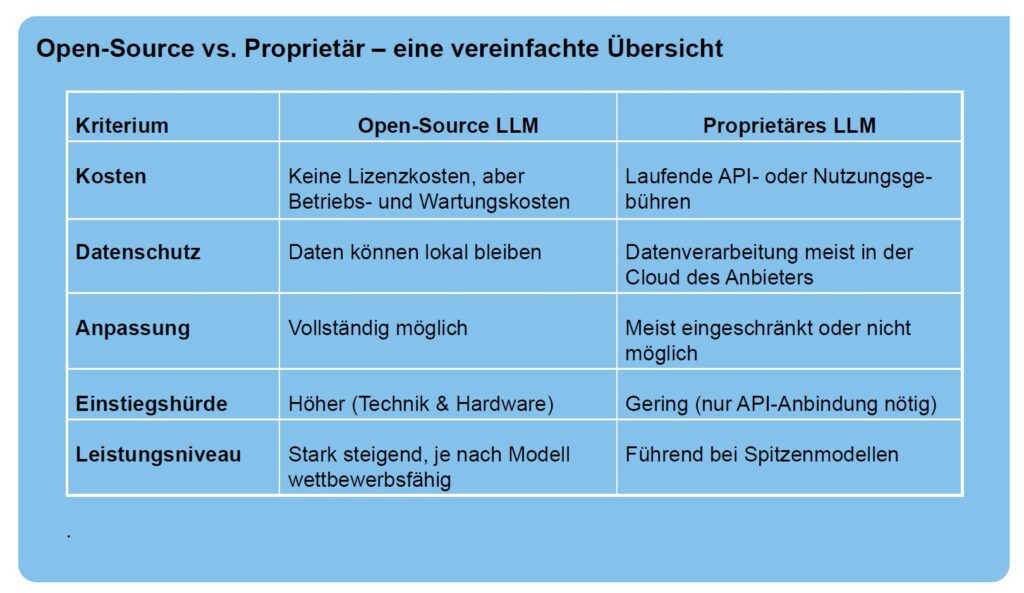
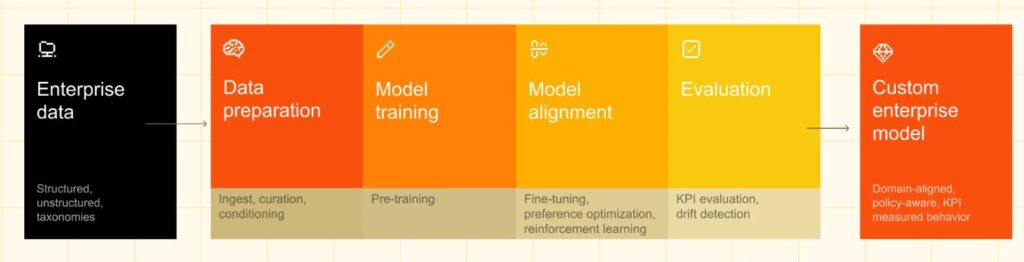
Gerade KMU sollten darauf achten, wenn sie Künstliche Intelligenz in ihre Prozesse einbinden wollen. XAI, Reasoning, Open Data und Open Source AI bieten hier geeignete Möglichkeiten, einen unternehmensspezifischen Mix zu finden.
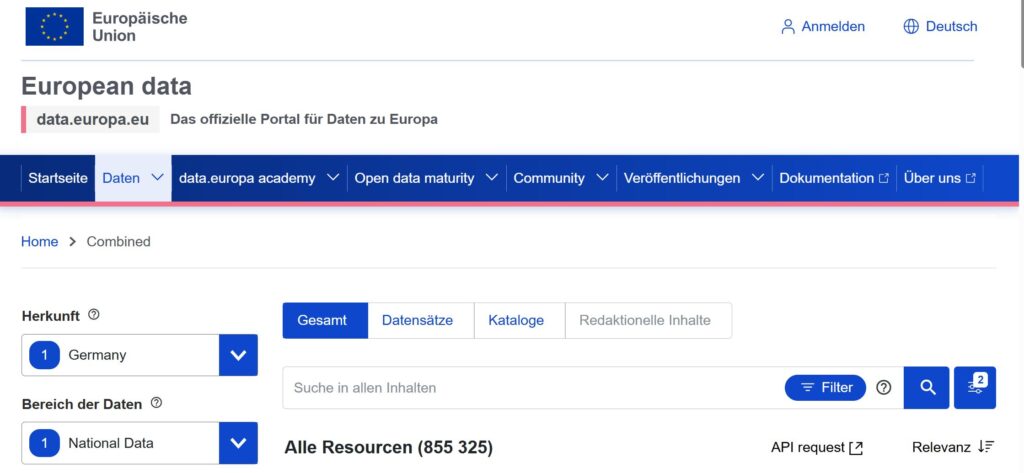
Open Data and Open Source AI – a perfect match – ganz im Sinne einer Digitalen Souveränität.