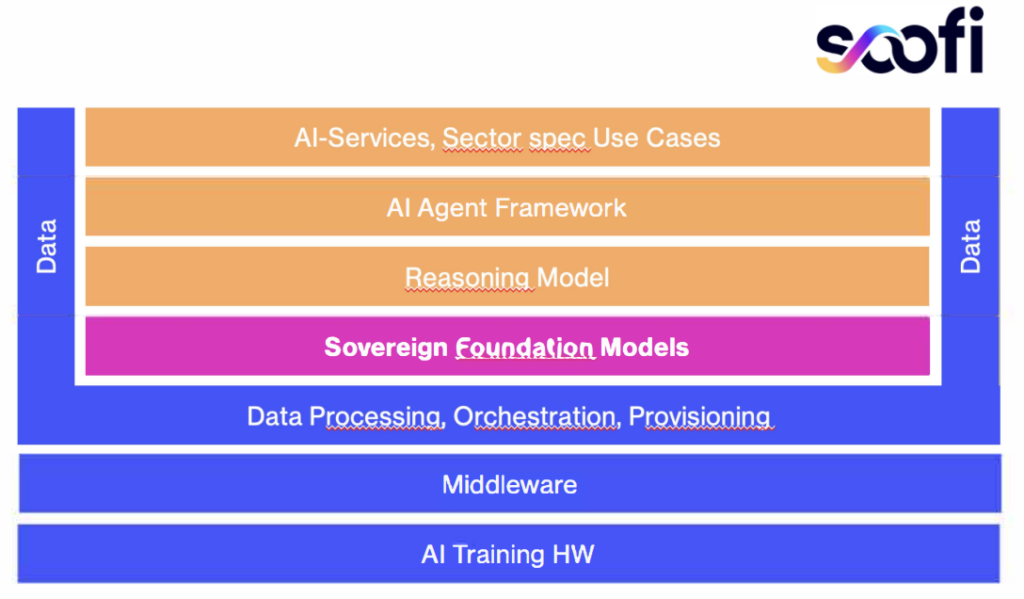
KI-Agenten sind aktuell in aller Munde. Gerade in Software-Unternehmen wurde schon früh damit angefangen, Agenten zu nutzen: KI-Agenten können bis zu 30% der realen Aufgaben eines Unternehmens autonom übernehmen.
Im Außenverhältnis, z.B. mit Kunden , wird es schon schwieriger, KI-Agenten einzusetzen, da hier weitergehende Herausforderungen zu bewältigen sind. Es wundert daher nicht, dass es an dieser Stelle Forschungsbedarf gibt.
In dem Projekt Loyal Agents arbeiten dazu beispielsweise das Stanford Digital Economy Lab und Consumer Report zusammen. Worum es ihnen geht, haben sie auf der Website Loyal Agents so formuliert:
„Agentic AI is transforming commerce and services; agents are negotiating, transacting and making decisions with growing autonomy and impact. While agents can amplify consumer power, there is also risk of privacy breaches, misaligned incentives, and manipulative business practices. Trust and security are essential for consumers and businesses alike“ (ebd.).
Dass Vertrauen und Sicherheit eine besonders wichtige Bedeutung in den Prozessen mit der Beteiligung von KI-Agenten haben, wird hier noch einmal deutlich – It all starts with Trust. Ähnliche Argumente kommen von Bornet, der sich für Personalized AI Twins ausspricht:
„Personal AI Twins represent a profound shift from generic to deeply personalized agents. Unlike today´s systems that may maintain the memory of past interactions but remain fundamentally the same for all users, true AI twins will deeply internalize an individual´s thinking patterns, values, communication style, and domain expertise“ (Bornet et al. 2025).
Möglicherweise können einzelne Personen in Zukunft mit Hilfe von Personalized AI Twins oder Loyal Agents ihre eigenen Ideen besser selbst entwickeln, oder sogar als Innovationen in den Markt bringen. Dabei empfiehlt sich aus meiner Sicht die Nutzung von Open Source AI – ganz im Sinne einer Digitalen Souveränität und im Sinne von Open User Innovation nach Eric von Hippel. Siehe dazu auch
Eric von Hippel (2017): Free Innovation
Von Democratizing Innovation zu Free Innovation