Über die Open Source AI-Modelle der Olmo2-Familie habe ich schon einmal in diesem Blogbeitrag geschrieben. Grundsätzlich soll mit diesen Modellen die Forschung an Sprachmodellen unterstützt werden. Anfang November hat Ai2 nun bekannt gegeben, dass mit OlmoEarth eine weitere Modell-Familie als Foundation Models (Wikipedia) zur Verfügung steht.
„OlmoEarth is a family of open foundation models built to make Earth AI practical, scalable, and performant for real-world applications. Pretrained on large volumes of multimodal Earth observation data“ (Source: Website).
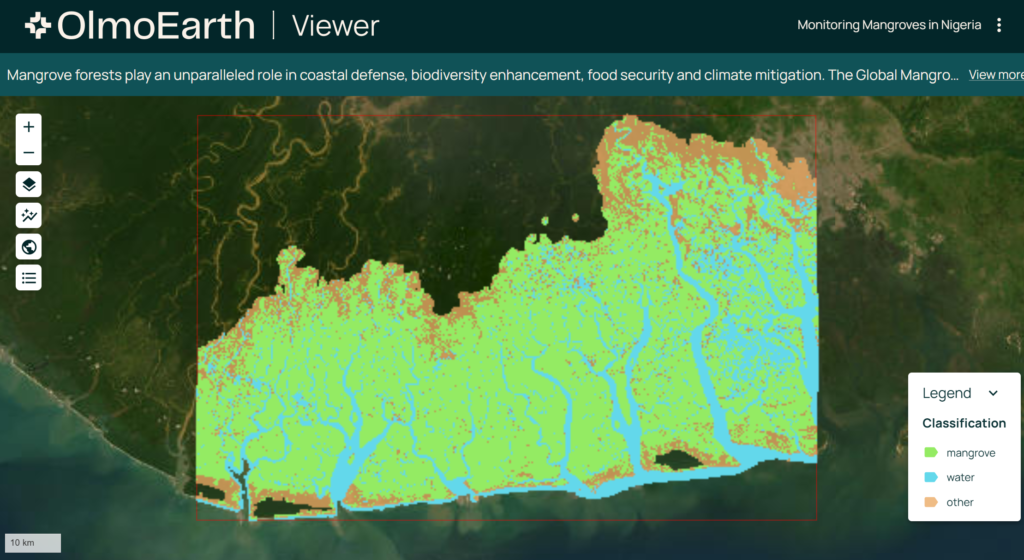
Es handelt sich also um eine offene, trainierte Modell-Familie, die zur Lösung realer Probleme (real world problems) beitragen sollen. Hier ein Beispiel von der Nutzung der Daten für eine Fragestellung in Nigeria:
Es gibt vier unterschiedliche Modelle. Interessant dabei ist, dass es auch kleine Modelle (Nano und Tiny) gibt, die kostengünstig sind, und schnell genutzt werden können:
Bei Innovationen sollten wir uns zunächst einmal klar machen, was im Unternehmenskontext darunter zu verstehen ist. Das Oslo Manual schlägt vor, Innovation wie folgt zu interpretieren:
„(…) a new or improved product or process (or combination thereof) that differs significantly from the unit’s previous products or processes and that has been made available to potential users (product) or brought into use by the unit (process)” (Oslo Manual 2018).
Dass Innovation u.a. eine Art Neu-Kombination von Existierendem bedeutet, ist vielen oft nicht so klar (combination thereof). Neue Ideen – und später Innovationen – entstehen oft aus vorhandenen Konzepten. oder Daten.
An dieser Stelle kommen nun die Möglichkeiten der Künstlichen Intelligenz (GenAI oder auch AI Agenten) ins Spiel. Mit KI ist es möglich, fast unendlich viele Neu-Kombinationen zu entwickeln, zu prüfen und umzusetzen. Das können Unternehmen nutzen, um ihre Innovationsprozesse neu zu gestalten, oder auch jeder Einzelne für seine eigenen Neu-Kombinationen im Sinne von Open User Innovation nutzen. Siehe dazu Von Democratizing Innovation zu Free Innovation.
Entscheidend ist für mich, welche KI-Modelle dabei genutzt werden. Sind es die nicht-transparenten Modelle der Tech-Unternehmen, die manchmal sogar die Rechte von einzelnen Personen, Unternehmen oder ganzer Gesellschaften ignorieren, oder nutzen wir KI-Modelle, die frei verfügbar, transparent und für alle nutzbar sind (Open Source AI)?
Mit Nextcloud haben wir eine Open Source Software auf unserem Server installiert, die je nach Bedarf mit Hilfe von Apps (Anwendungen) erweitert werden kann. Für die Verbesserung der Produktivität gibt es zunächst einmal die App Flow, mit der einfache Abläufe automatisiert werden können.
Sind die Ansprüche etwas weitreichender, bietet sich die App Workflow an, die wir auch installiert haben. Die App basiert auf Windmill und ermöglicht es uns, Abläufe (Workflows) per bekannter Symbole darzustellen. In der Abbildung sind links die zwei einfachen Symbole „Input“ und „Output“ zu sehen. Rechts daneben werden die Details zu den einzelnen Button und Schritte angezeigt – das Prinzip dürfte klar sein, Einzelheiten zu den vielfältigen Optionen erspare ich mir daher.
Es ist immer wieder erstaunlich, wie schnell viele Apps auf Open Source Basis zur Verfügung stehen, und je nach Bedarf genutzt werden können. Aktuell ist die Anzahl der generierbaren Workflows über die freie Version von Nextcloud noch begrenzt. Alternativ könnten wir auch Windmill direkt auf unserem Server installieren: Self-host Windmill. Ähnlich haben wir es schon mit OpenProject gemacht. Wobei es dann aus der Anwendung heraus möglich ist, auf Nextcloud-Daten zuzugreifen.
Ob wir das machen hängt davon ab, ob wir mit Workflow in Zukunft weiterarbeiten, oder alle Arten von Flows direkt in Langflow abbilden, da wir dort den direkten Übergang zu KI-Agenten haben. Alle Open Source Anwendungen laufen auf unseren Servern, sodass alle generierten Daten auch bei uns bleiben. Ganz im sinne einer Digitalen Souveränität.
Eigener Screenshot vom Langflow-Arbeitsbereich, inkl. der Navigation auf der linken Seite
Langflow haben wir als Open Source Anwendung auf unseren Servern installiert. Mit Langflow ist es möglich, Flows und Agenten zu erstellen – und zwar einfach mit Drag&Drop. Na ja, auch wenn es eine gute Dokumentation und viele Videos zu Langflow gibt, steckt der „Teufel wie immer im Detail“.
Wenn man mit Langflow startet ist es erst einmal gut, die Beispiele aus den Dokumentationen nachzuvollziehen. Ich habe also zunächst damit begonnen, einen Flow zu erstellen. Der Flow unterscheidet sich von Agenten, auf die ich in den nächsten Wochen ausführlicher eingehen werde.
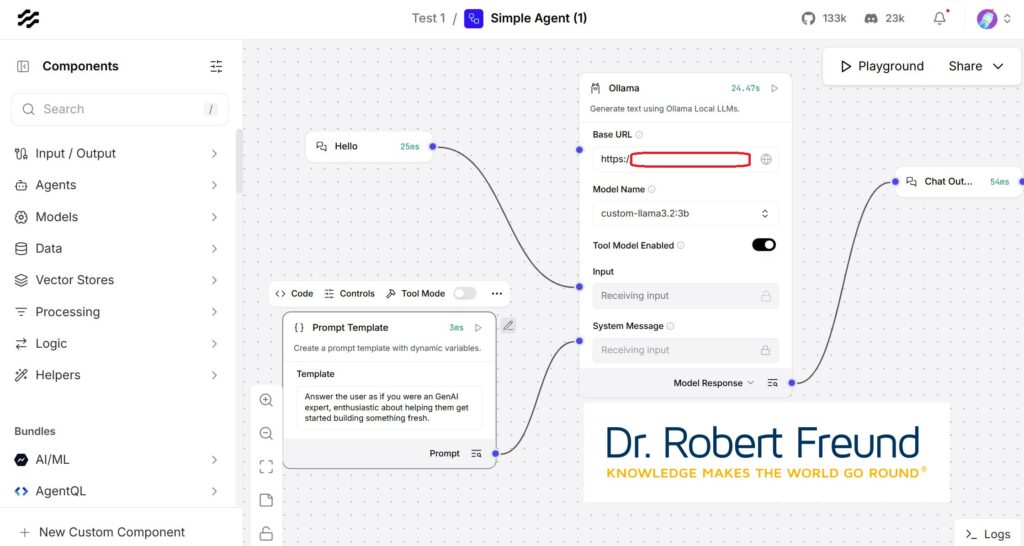
Wie in der Abbildung zu sehen ist, gibt es einen Inputbereich, das Large Language Model (LLM) oder auch ein kleineres Modell, ein Small Language Model (SLM). Standardmäßig sind die Beispiele von Langflow darauf ausgerichtet, dass man OpenAI mit einem entsprechenden API-Key verwendet. Den haben wir zu Vergleichszwecken zwar, doch ist es unser Ziel, alles mit Open Source abzubilden – und OpenAI mit ChatGPT (und andere) sind eben kein Open Source AI.
Um das zu erreichen, haben wir Ollama auf unseren Servern installiert. In der Abbildung oben ist das entsprechende Feld im Arbeitsbereich zu sehe,n. Meine lokale Adresse für die in Ollama hinterlegten Modelle ist rot umrandet unkenntlich gemacht. Unter „Model Name“ können wir verschiedene Modelle auswählen. In dem Beispiel ist es custom-llama.3.2:3B. Sobald Input, Modell und Output verbunden sind, kann im Playground (Botton oben rechts) geprüft werden, ob alles funktioniert. Das Ergebnis sieht so aus:
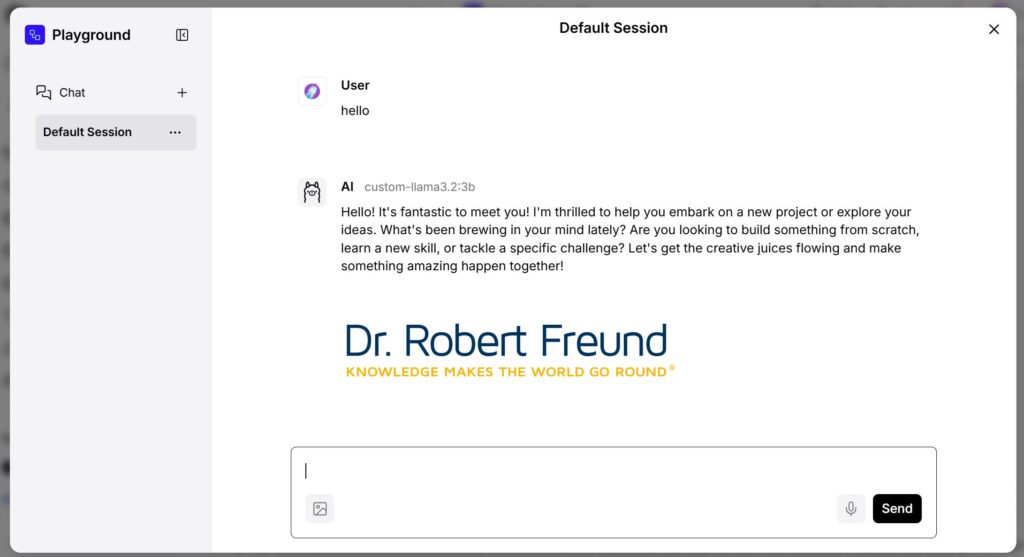
Screenshot vom Playground: Ergebnis eines einfachen Flows in Langflow
Es kam mir jetzt nicht darauf an, komplizierte oder komplexe Fragen zu klären, sondern überhaupt zu testen, ob der einfache Flow funktioniert. Siehe da: Es hat geklappt!
Alle Anwendungen (Ollama und Langflow) sind Open Source und auf unseren Servern installiert. Alle Daten bleiben auf unseren Servern. Wieder ein Schritt auf dem Weg zur Digitalen Souveränität.
Um digital souveräner zu werden, haben wir seit einiger Zeit Nextcloud auf einem eigenen Server installiert – aktuell in der Version 32. Das ist natürlich erst der erste Schritt, auf den nun weitere folgen – gerade wenn es um Künstliche Intelligenz geht.
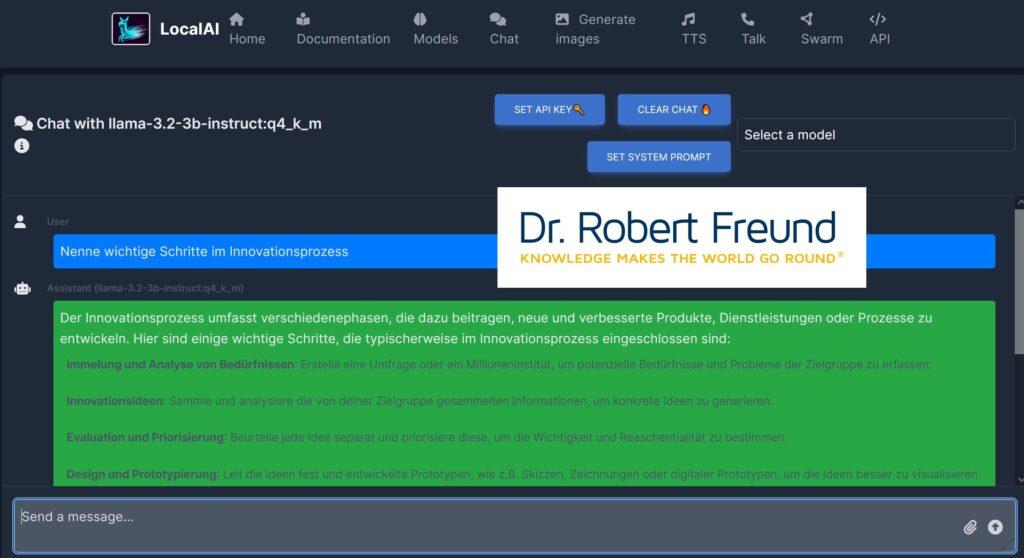
Damit wir auch bei der Nutzung von Künstlicher Intelligenz digital souverän bleiben, haben wir zusätzlichLocalAIinstalliert. Dort ist es möglich, eine Vielzahl von Modellen zu testen und auszuwählen. In der folgenden Abbildung ist zu sehen, dass wir das KI-Modell llama-3.2-3B-instruct:q4_k_m für einen Chat ausgewählt haben. In der Zeile „Send a massage“ wurde der Prompt „Nenne wichtige Schritte im Innovationsprozess“ eingegeben. Der Text wird anschließend blau hinterlegt angezeigt. In dem grünen Feld ist ein Teil der Antwort des KI-Modells zu sehen.
LocalAI auf unserem Server: Ein Modell für den Chat ausgewählt
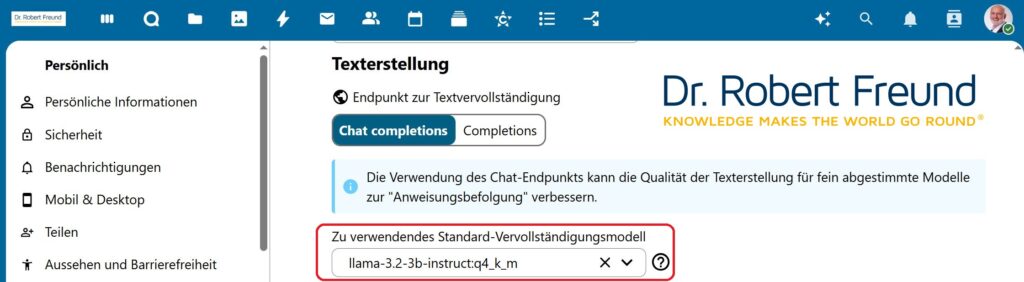
Im nächsten Schritt geht es darum, das gleiche KI-Modell im Nextcloud Assistant zu hinterlegen. Der folgende Screenshot zeigt das Feld (rot hervorgehoben). An dieser Stelle werden alle in unserer LocalAI hinterlegten Modelle zur Auswahl angezeigt, sodass wir durchaus variieren könnten. Ähnliche Einstellungen gibt es auch für andere Funktionen des Nextcloud Assistant.
Screenshot: Auswahl des Modells für den Nextcloud Assistenten in unserer Nextcloud – auf unserem Server
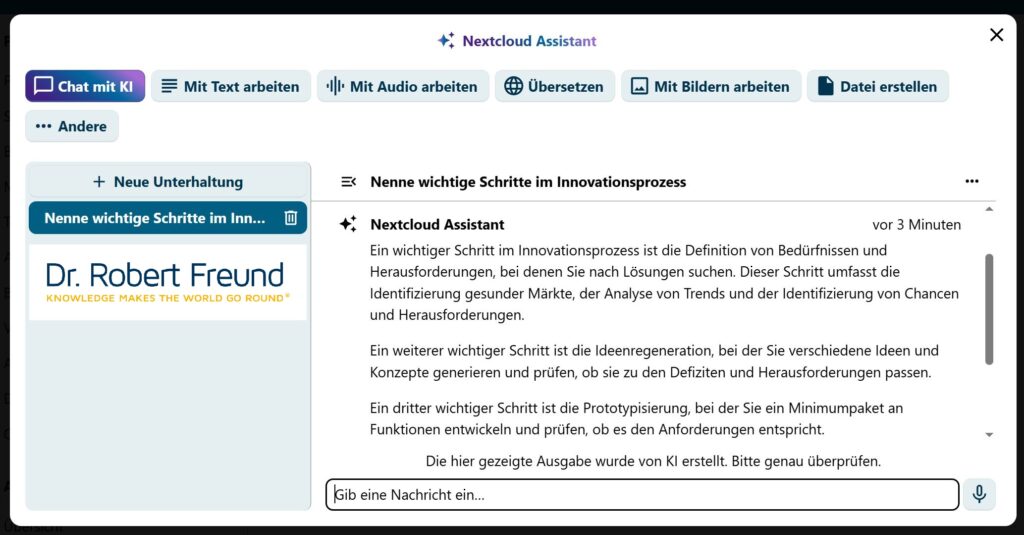
Abschließend wollen wir natürlich auch zeigen, wie die Nutzung des hinterlegten KI-Modells in dem schon angesprochenen Nextcloud Assistant aussieht. Die folgende Abbildung zeigt den Nextcloud Assistant in unserer Nextcloud mit seinen verschiedenen Möglichkeiten – eine davon ist Chat mit KI. Hier haben wir den gleichen Prompt eingegeben, den wir schon beim Test auf LocalAI verwendet hatten (Siehe oben).
Screenshot von dem Nextcloud Assistant mit der Funktion Chat mit KI und der Antwort auf den eigegebenen Prompt
Der Prompt ist auf der linken Seite zu erkennen, die Antwort des KI-Modells (llama-3.2-3B-instruct:q4_k_m) ist rechts daneben wieder auszugsweise zu sehen. Weitere „Unterhaltungen“ können erstellt und bearbeitet werden.
Das Zusammenspiel der einzelnen Komponenten funktioniert gut. Obwohl wir noch keine speziellen KI-Server hinterlegt haben, sind die Antwortzeiten akzeptabel. Unser Ziel ist es, mit wenig Aufwand KI-Leistungen in Nextcloud zu integrieren. Dabei spielen auch kleine, spezielle KI-Modelle eine Rolle, die wenig Rechenkapazität benötigen.
Alles natürlich Open Source, wobei alle Daten auf unseren Servern bleiben.
Wir werden nun immer mehr kleine, mittlere und große KI-Modelle und Funktionen im Nextcloud Assistant testen. Es wird spanned sein zu sehen, wie dynamisch diese Entwicklungen von der Open Source Community weiterentwickelt werden.
AI2 ist eine Non-Profit Organisation, die Künstliche Intelligenz für die vielfältigen gesellschaftlichen Herausforderungen entwickelt. Das 2014 in Seattle gegründete Institut stellt dabei auch verschiedene Open Source KI-Modelle zur Verfügung – u.a. auch OLMo2.
„OLMo 2 is a family of fully-open language models, developed start-to-finish with open and accessible training data, open-source training code, reproducible training recipes, transparent evaluations, intermediate checkpoints, and more“ (Quelle).
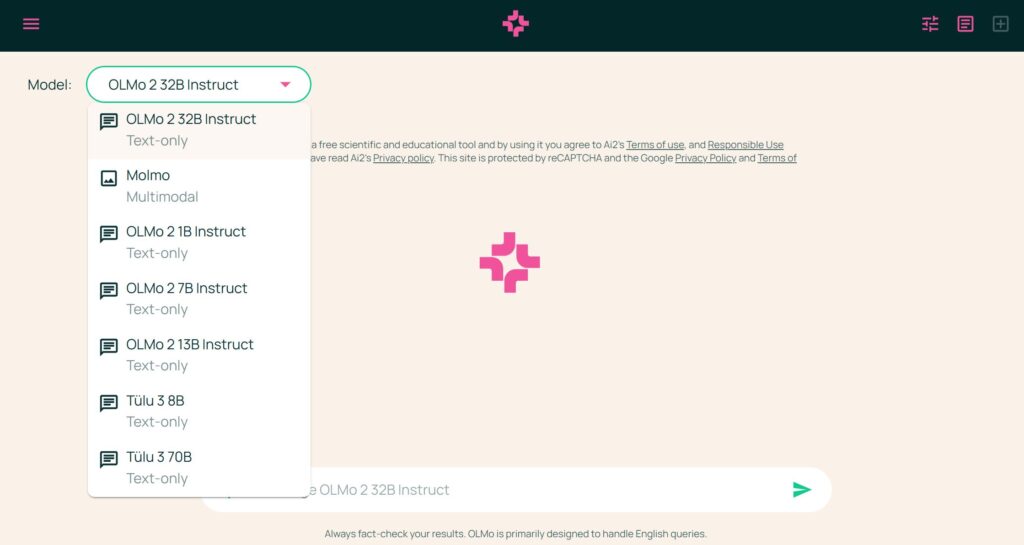
Wenn man die von AI2 veröffentlichten KI-Modelle einmal testen möchte, kann man das nun in einem dafür eingerichteten Playground machen. Wie in der Abbildung zu erkennen, können Sie einzelne Modelle auswählen, und mit einem Prompt testen. Der direkte Vergleich der Ergebnisse zeigt Ihnen, wie sich die Modelle voneinander unterscheiden.
Eigener Screenshot: Installation von Open Euro LLM 9B Instruct in unserer LocalAI
Es ist schon erstaunlich, wie dynamisch sich länderspezifische (Polen, Spanien, Schweden usw.) Large Language Models (LLMs) und europäische LLMs entwickeln. In 2024 wurde Teuken 7B veröffentlicht, über das wir in unserem Blog auch berichtet hatten. Siehe dazu Open Source AI-Models for Europe: Teuken 7B – Training on >50% non English Data. Weiterhin haben wir damals auch schon Teuken 7B in unsere LocalAI integriert.
Nun also Open EuroLLM, ein Large language Modelmade in Europebuilt to support allofficial 24 EU languages. Die generierten Modelle sind Multimodal, Open Source, High Performance und eben Multilingual. Interessant dabei ist, dass damit Innovation angestoßen werden sollen.
Das große Modell eurollm-9b-instruct haben wir in unserer LocalAI installiert. Die Abbildung zeigt den Installationsprozess. Ich bin sehr gespannt darauf, wie sich das Modell in unserer LocalAI im Vergleich zu anderen Modellen schlägt. Möglicherweise werden wir auch noch einmal das kleine Modell 1.7B installieren, das auf Huggingface verfügbar ist.
Alle Modelle, die wir in unserer LocalAI installieren, können wir auch je nach Anwendung in unserer Nextcloud über den Nextcloud Assistenten und der Funktion „Chat mit KI“ nutzen. Dabei bleiben alle generierten Daten auf unserem Server – ganz im Sinne einer Digitalen Souveränität.
Eigener Screenshot von unserer Nextcloud mit der App „Collective“
Unsere Nextcloud (Open Source) ist ein zentrales Element auf dem Weg zur Digitalen Souveränität. Dazu gehören nicht nur Möglichkeiten, LocalAI oder auch KI-Agenten zu nutzen, sondern auch Anwendungen (Apps), die wir im Tagesgeschäft benötigen.
Zum Beispiel haben wir die App Collective installiert und aktiviert. In der Abbildung ist ein Screenshot von einer angelegten Startseite zum Thema „Agentic AI Company“ zu sehen.
Zu diesem Bereich kann ich nun verschiedene Teilnehmer zuordnen/einladen. Dabei können alle die jeweiligen Seiten wie in einem Wiki kollaborativ bearbeiten. Diese Möglichkeit geht über die reine Bereitstellung eines gemeinsamen Ordners hinaus und unterstützt die gemeinsame Entwicklung von (expliziten) Wissen.
Wichtig dabei ist, dass alle Daten, die hier gemeinsam geteilt und bearbeitet werden, auf unserem Server bleiben.
Natürlich können auch andere Wiki-Apps (Open Source) in die Nextcloud eingebunden werden. Jeder kann somit seine Nextcloud so konfigurieren, wie er möchte.
Wenn aber der erste Schritt zur Nutzung von Künstlicher Intelligenz Vertrauen sein sollte (Thomas et al. 2025), sollte man sich als Privatperson, als Organisation, bzw. als Verwaltung nach Alternativen umsehen.
Wie Sie als Leser unseres Blogs wissen, tendieren wir zu (wirklichen) Open Source AI Modellen, doch in dem Buch von Thomas et al. (2025) ist mir auch der Hinweis auf das von IBM veröffentlichte KI-Modell Granite aufgefallen. Die quelloffene Modell-Familie kann über Hugging Face, Watsonx.ai oder auch Ollama genutzt werden.
Das hat mich neugierig gemacht, da wir ja in unserer LocalAI Modelle dieser Art einbinden und testen können. Weiterhin haben wir ja auch Ollama auf unserem Server installiert, um mit Langflow KI-Agenten zu erstellen und zu testen.
Im Fokus der Granite-Modellreihe stehen Unternehmensanwendungen, wobei die kompakte Struktur der Granite-Modelle zu einer erhöhten Effizienz beitragen soll. Unternehmen können das jeweilige Modell auch anpassen, da alles über eine Apache 2.0-Lizenz zur Verfügung gestellt wird.
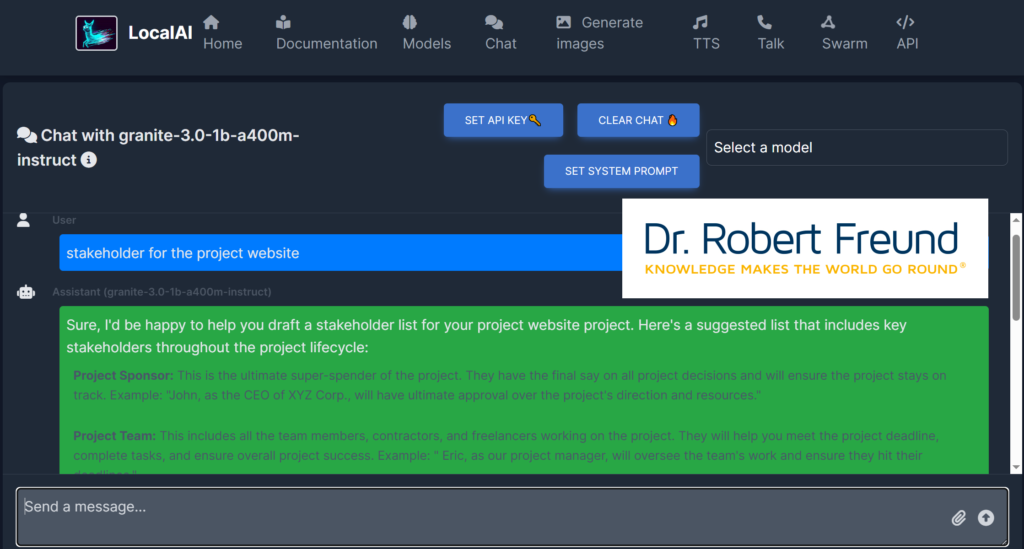
Wie Sie der Abbildung entnehmen können, haben wir Granite 3.0 -1b-a400m in unsere lokale KI (LocalAI) eingebunden. Das geht relativ einfach: Wir wählen aus den aktuell mehr als 1.000 Modellen das gewünschte Modell zunächst aus. Anschließend brauchen wir nur auf „Installieren“ zu klicken, und das Modell steht in der Auswahl „Select a model“ zur Verfügung.
Im unteren Fenster (Send a message) habe ich testweise „Stakeholder for the project Website“ eingegeben. Dieser Text erscheint dann blau hinterlegt, und nach einer kurzen Zeit kommen dann schon die Ergebnisse, die in der Abbildung grün hinterlegt sind. Wie Sie am Balken am rechten Rand der Grafik sehen können, gibt es noch mehrere Stakeholder, die man sieht, wenn man nach unten scrollt.
Ich bin zwar gegenüber Granite etwas skeptisch, da es von IBM propagiert wird, und möglicherweise eher zu den Open Weighted Models zählt, doch scheint es interessant zu sein, wie sich Granite im Vergleich zu anderen Modellen auf unserer LocalAI-Installation schlägt.
Bei allen Tests, die wir mit den hinterlegten Modellen durchführen, bleiben die generierten Daten alle auf unserem Server.
Wenn man also in Nextcloud eine Datei öffnen möchte, hat man die Optionen „Neue Tabelle“ (wie Excel), „Neue Textdatei“ (wie Word), „Neue Präsentation“ (wie Power Point), „Neues Diagramm“ und eben ein „Neues Whiteboard“ zu erstellen. Es ist praktisch, dass diese Möglichkeit direkt integriert ist.
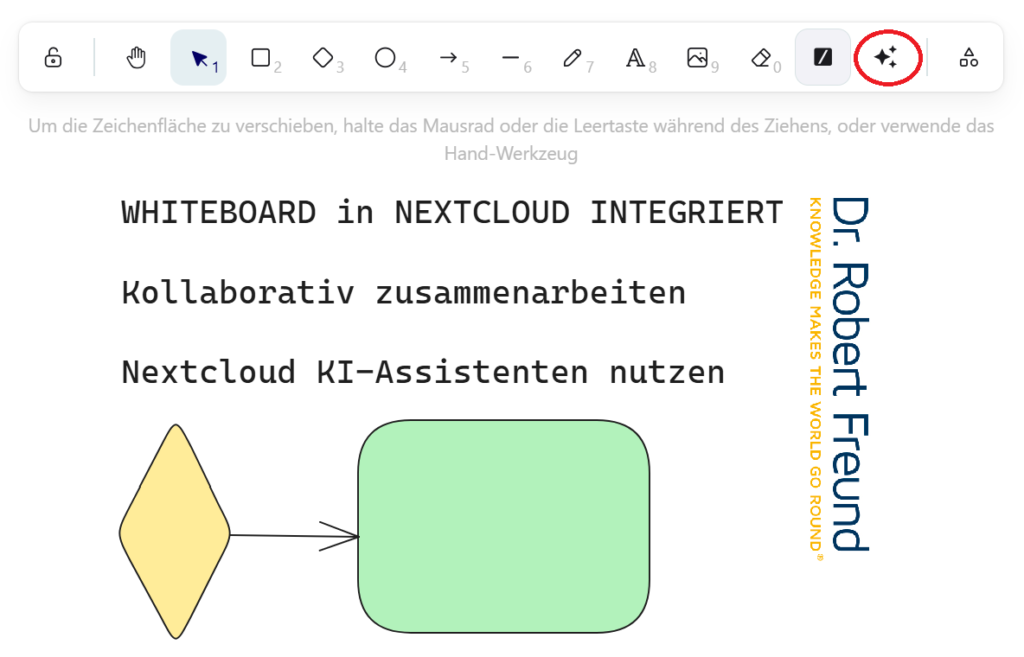
Das Whiteboard selbst basiert auf dem von mir schon 2022 vorgestellten tldraw, das mir damals schon wegen seiner Einfachheit und Kompaktheit gefallen hat. Jetzt ist es also in Nextcloud eingebunden worden. Es gibt zu dem Whiteboard eine Bibliothek, in der man alle selbst erstellten Vorlagen hinterlegen, oder auch im Netz verfügbare Vorlagen einbinden kann. Natürlich gibt es nicht so viele frei verfügbare Vorlagen wie bei Miro oder Mural, doch hat das in Nextcloud integrierte Whiteboard die Vorteile, dass es in einer umfangreichen Kollaborationsplattform integriert und Open Source basiert ist, und alle Daten auf dem eigenen Server laufen.
Es gibt neben den von anderen Whiteboards bekannten Funktionen, in der Zwischenzeit auch einen Botton, um den Nextcloud KI-Assistenten mit in das Whiteboard einzubinden. In der Abbildung habe ich den Botton rot hervorgehoben.
Das in dem Assistenten hinterlegte KI-Modell können wir selbst festlegen, da wir die Modelle in unserer LocalAI vorliegen haben. Somit laufen alle Anwendungen auf unseren Servern und alle Daten bleiben auch bei uns. Ganz im Sinne der Reduzierung der oftmals noch vorherrschenden Digitalen Abhängigkeit von den den etablierten Anwendungen meist amerikanischer Tech-Konzerne.
Weg von der Digitalen Abhängigkeit und hin zu einer Digitalen Souveränität.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.