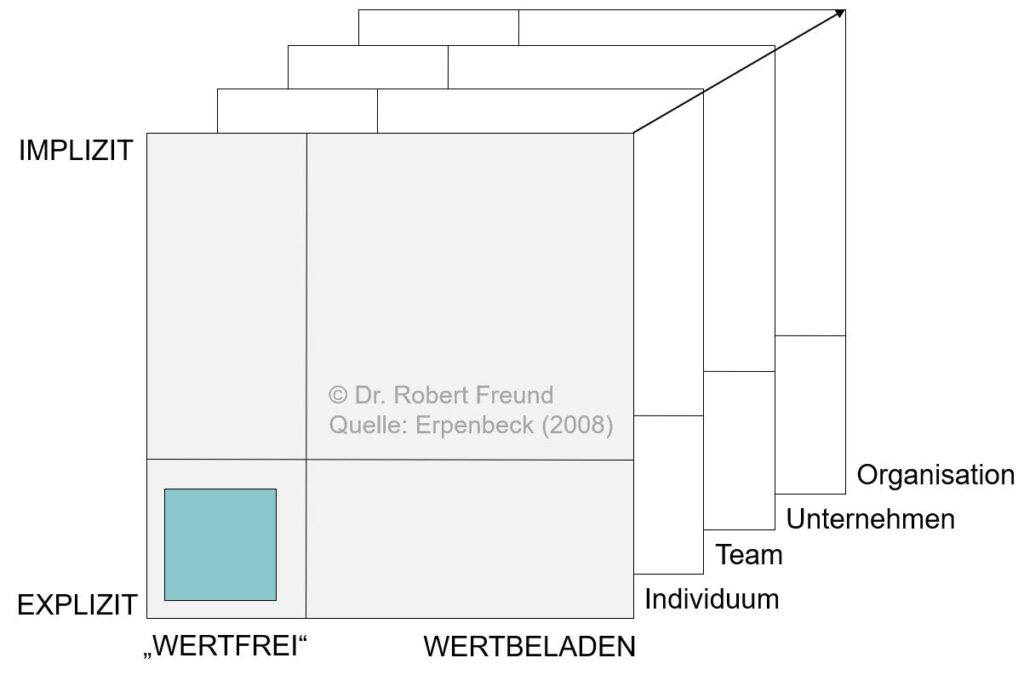
Diesmal möchte ich mich mit dem Verhältnis zwischen „Wissen„, „Werten“ und „Organisationsebenen“ befassen. In der Abbildung ist zunächst zu erkennen, dass Wissen implizit oder auch explizit vorliegen kann .
Das explizierbare Wissen ist häufig „wertfrei“, wodurch es gut formuliert und digitalisiert usw. werden kann. Je „wertbeladener“ Wissen wird, umso eher handelt es sich um implizites Wissen – beispielsweise einer Person (Individuum).
Natürlich können diese Überlegungen auch auf der Teamebene, der Unternehmensebene oder organisationalen (auch Netzwerk-) Ebene angestellt werden. Wie die Abbildung qualitativ auch aufzeigt. ist der Anteil des expliziten, wertfreien Wissens im Vergleich zum impliziten Wissen relativ gering.
„Besonders bemerkenswert ist die Asymmetrie der Quadranten (…). Ca. 72% unserer Entscheidungen basieren nach KARNER auf impliziten Wissen (tacit knowledge) in Form von Werten, Symbolen, Metaphern, Macht, Prestige, usw. Nach einer Studie der Fraunhofer Gesellschaft liegen sogar 85% des Unternehmenswissens in impliziter Form vor“ (Erpenbeck 2008).
Aus diesen Überlegungen leitet sich auch ab, wie gerade mit impliziten, wertbeladenen Wissen umgegangen werden sollte:
„Je mehr Wissen wertbeladen und implizit ist, desto eher muss es mit Hilfe psychologischer bzw. sozialwissenschaftlicher Methoden gewonnen und, was die Wertanteile angeht, psychisch interiorisiert bzw. in Sozialisationsprozessen internalisiert werden“ (Erpenbeck 2008).
Der Wertebezug von Wissen ist gerade in Zeiten von Künstlicher Intelligenz wichtig, da Werte Ordner sozialer Komplexität sind. Wenn sich also die Werte in der Europäischen Union und die Werte der oft genutzten KI-Modelle stark unterscheiden, hat das Auswirkungen auf alle Ebenen des Wissenssystems.
Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich.