Sir Roger Penrose ist u.a. Mathematiker und theoretischer Physiker. In 2020 hat er eine Hälfte des Nobelpreises für Physik erhalten. Penrose hat sich darüber hinaus recht kritisch mit Künstlicher Intelligenz auseinandergesetzt.
Er ist zu der Auffassung gelangt, dass man nicht von Künstlicher Intelligenz (Artificial Intelligence), sondern eher von Künstlicher Cleverness (Artificial Cleverness) sprechen sollte. Dabei leitet er seine Erkenntnisse aus den beiden Gödelschen Unvollständigkeitssätzen ab. In einem Interview hat Penrose seine Argumente dargestellt:
Sir Roger Penrose, Gödel’s theorem debunks the most important AI myth. AI will not be conscious, Interview, YouTube, 22 February 2025. This Is World.
Available at: https://www.youtube.com/watch?v=biUfMZ2dts8
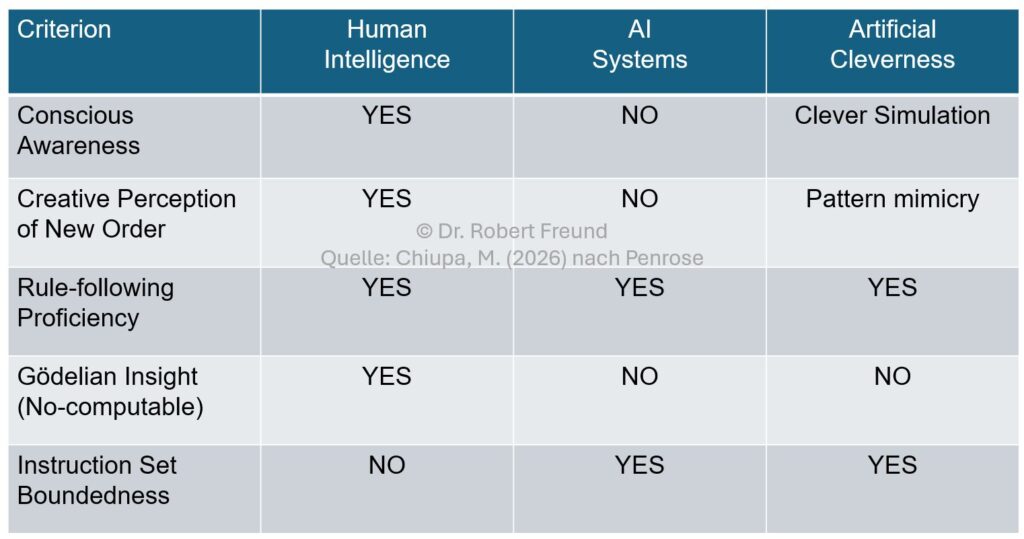
Da das alles ziemlich schwere Kost ist, hat Martin Chiupa (2026) via LinkedIn eine Übersicht (Abbildung) erstellt, die anhand verschiedener Kriterien Unterschiede zwischen Human Intelligence, AI Systems und Artificial Cleverness aufzeigt.
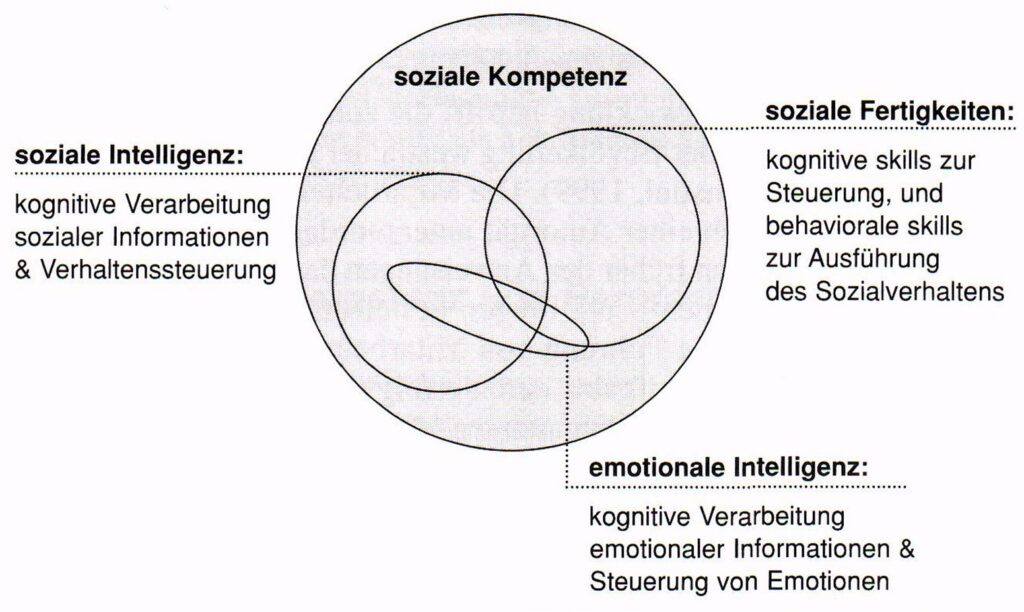
Penrose steht mit seiner Auffassung nicht alleine. Siehe dazu auch Künstliche Intelligenz – Menschliche Kompetenzen: Anmerkungen zu möglichen Kategorienfehler.