In dem Buch Muldoon, J., Graham, M., Cant, C. (2025) Feeding the Machine geht es den Autoren darum, zu hinterfragen, wie die großen KI-Modelle (LLM: Large Language Models) mit ihren riesigen Datenmengen entstehen, und von großen Unternehmen für ihre geschäftlichen Aktivitäten genutzt werden.
„Das ist aus Sicht von Muldoon, Graham und Cant auch das grundsätzliche Problem der KI-Entwicklung: dass sie vor allem von wenigen mächtigen Akteuren in deren Eigeninteresse entwickelt und genutzt werde. Die Kapitalintensität von KI führe dazu, dass sich Machtstrukturen weiter verfestigen, da nur wenige Unternehmen weltweit das Geld, die Hardware und das Knowhow besitzen, um die Entwicklung voranzutreiben. Durch die Arbeit dieser Unternehmen würden auch koloniale Strukturen aufrechterhalten, schreiben sie. Weil sich Arbeitskräfte im globalen Süden gezwungen sähen, für sehr wenig Geld unter schlechten Bedingungen zu arbeiten, während die hohen Gewinne in die Kassen der Konzerne und Investoren fließen“ (Scherer, K. (2025): KI-Erklärwerk und Kapitalismuskritik, Deutschlandfunk, Andruck, 30.06.2025 | PDF).
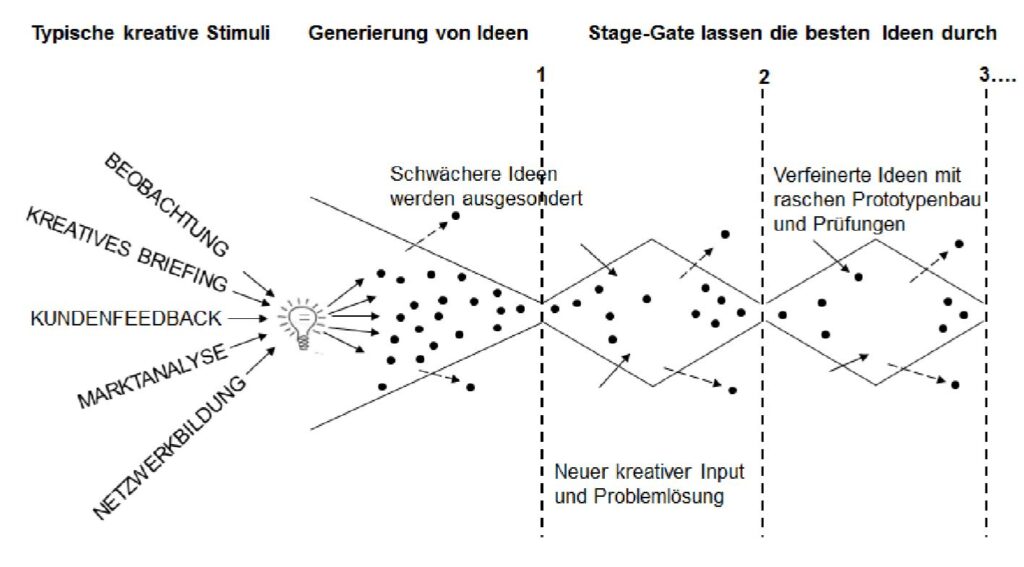
Es ist daher gut, dass sich in den letzten mehr als 20 Jahren weltweit Alternativen entwickelt haben, die frei verfügbare Daten in frei verfügbaren KI-Modellen zur Verfügung stellen (Open Data and Open Source AI – a perfect match). Je mehr diese genutzt werden, umso weniger Marktmacht haben die großen Tech-Konzerne. Es wundert daher nicht, dass diese an alternativen Entwicklungen wenig interessiert sind, und versuchen eine Art open washing mit ihren Modellen zu betreiben. Siehe dazu auch
Die erfolgreiche Open Source KI Geschichte
Künstliche Intelligenz – It All Starts with Trust
Künstliche Intelligenz lässt die meisten Sprachen und kulturellen Besonderheiten außen vor