Es ist erstaunlich, dass es vielen Privatpersonen, Unternehmen und Öffentlichen Verwaltungen immer noch schwer fällt, sich von den kommerziellen Software-Angeboten zu lösen, um Digitale Souveränität zu erreichen Der Grund ist oftmals eine Gewöhnung an die jeweiligen Tools und damit auch eine gewisse Abhängigkeit.
Ein Wechsel zu Open Source Software wäre für viele mit Aufwand verbunden. Solche Switching Cost sind mit der Zeit von den etablierten Software-Unternehmen nach und nach immer weiter erhöht worden. Siehe dazu auch Es ist so bequem, unmündig zu sein.
Darüber hinaus gibt es auch Vorbehalte gegenüber Open Source Software, obwohl die Codebasis von Software sage und schreibe zu 97% Open Source Software enthält – auch kommerzielle Software.
„According to the 2025 Black Duck Open Source Security and Analysis Report, 97% of codebases scanned contained open source software“ (Carlber, A. N (2026) Open Source in Europe Amid Geopolitical Tensions, in Eclipse Foundation).
Wenn also fast alle Software zu einem so großen Anteil aus Open Source Software in ihrer Codebasis bestehen, sollten sich alle einmal überlegen, ob die Vorbehalte gegenüber Open Source Software heute noch angebracht sind.
In der Zwischenzeit erkennen immer mehr Personen, Unternehmen und Öffentliche Verwaltungen, dass der Nutzen von Open Source Software die Kosten deutlich übersteigt.
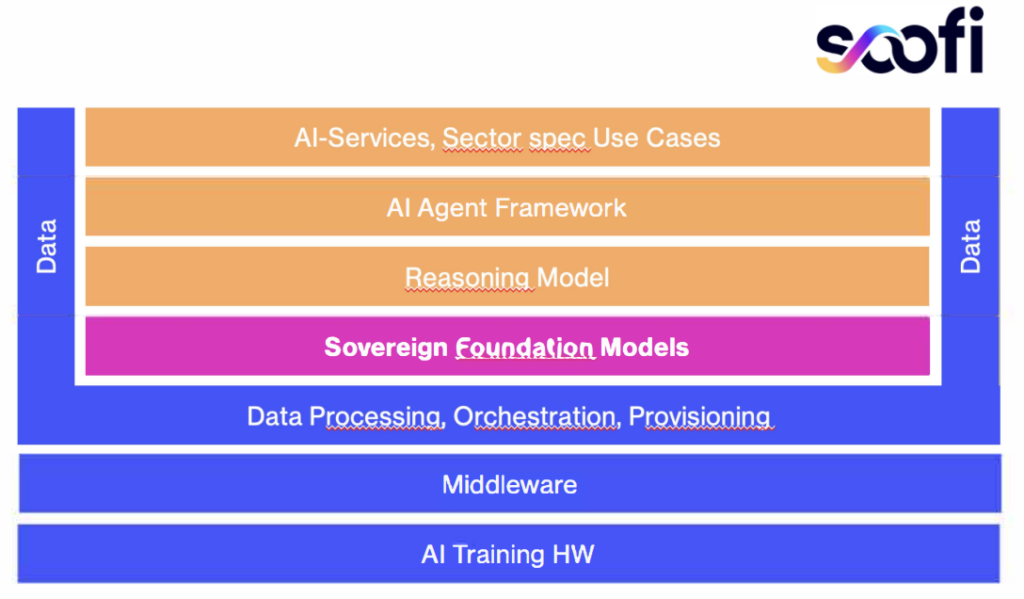
Auch zeigt die erfolgreiche Open Source KI Geschichte, dass Open Source sogar auf dem Gebiet der Künstlichen Intelligenz wettbewerbsfähig ist.

Auf der internationalen Konferenz MCP 2026 (16.-19.09.2026, Balatonfüred, Ungarn) gehe ich darauf in zwei Paper ein:
Open-Source AI for Open User Innovation: Designing a Personal Fabrication Framework
Digital Sovereignty and Open-Source AI: The European Way for Innovative SMEs