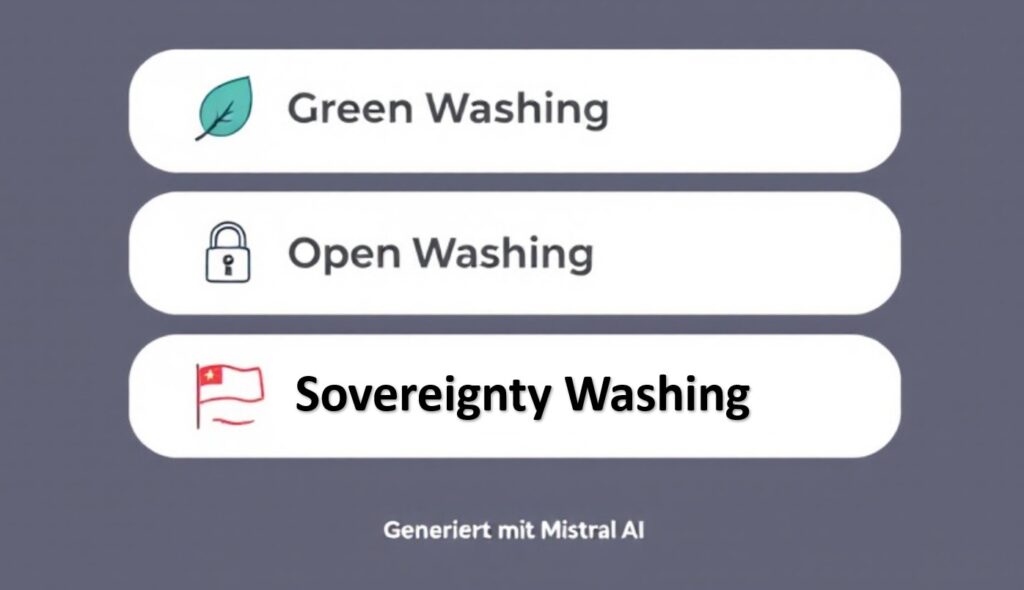
Na ja, wir alle kennen das Green Washing, Dabei geht es darum, dass sich Unternehmen als unweltfreundlich und umweltbewusst darstellen, es allerdings nicht sind.
In der Zwischenzeit kommt noch das Open Washing bei KI-Modellen hinzu. Gemeint ist hier, dass sich Unternehmen das Attribut „Open Source AI“ geben, die Modelle allerdings eher Cloused Source Modelle sind. Siehe dazu die veröffentlichte Definition zu Open Source AI.
Nun kommt noch das Sovereignty Washing hinzu. Nachdem in den letzten Jahren immer klarer wurde, dass wir uns in Europa in eine gefährliche digitale Abhängigkeit begeben haben, ist ein Trend in Richtung Digitale Souveränität auf dem Markt deutlich zu erkennen. Nun wollen (natürlich) Marktteilnehmer, die eher für Closed Source Angebote bekannt sind, von diesem Trend profitieren und verpassen ihren Angeboten das Lable „Souveränität“ oder in englischer Sprache „Sovereignty“.
„Gemeint sind Angebote, die europäische Kontrolle versprechen, aber zentrale Abhängigkeiten fortschreiben. Anbieter werben mit Rechenzentren in der EU, lokalen Tochtergesellschaften oder souverän klingenden Produktnamen. Zugleich bleiben Konzernstrukturen, Administrationsrechte, technische Steuerung oder rechtliche Zugriffspfade außerhalb Europas bestehen“ (Myra Security GmbH, 2026).
Wie bei Greenwashing oder Open Washing ist auch hier keine Digitale Souveränität drin, wo Digitale Souveränität draufsteht. Wie können Sie das überprüfen, ob ein Angebot ein Höchstmaß an Digitaler Souveränität bietet?
„Ein Höchstmaß an Digitaler Souveränität bietet eine digitale Lösung dann, wenn sie:
rechtssicher/DSGVO-konform betrieben werden kann (bspw. ohne Zugriff durch ausländische Behörden auf Daten).
Wechselfähigkeit ermöglicht (d. h. kein Vendor-Lock-in besteht),
Kontrolle sichert (auch bei Ausfall, Sperrung oder Wechsel von Dienstleistern),
Transparenz bietet (z. B. durch einsehbaren Quellcode)
und anpassbar und gestaltbar ist (z. B. durch Weiterentwicklung in der Community oder durch Dienstleister).“
Quelle: Zentrum für Digitale Souveränität der Öffentlichen Verwaltung (ZenDiS) GmbH (2025): Souveränitäts-Washing bei Cloud-Diensten erkennen. Warum Digitale Souveränität mehr ist als ein Standortversprechen | Whitepaper (PDF).
Siehe dazu auch Der Kill-Switch und Digitale Souveränität.
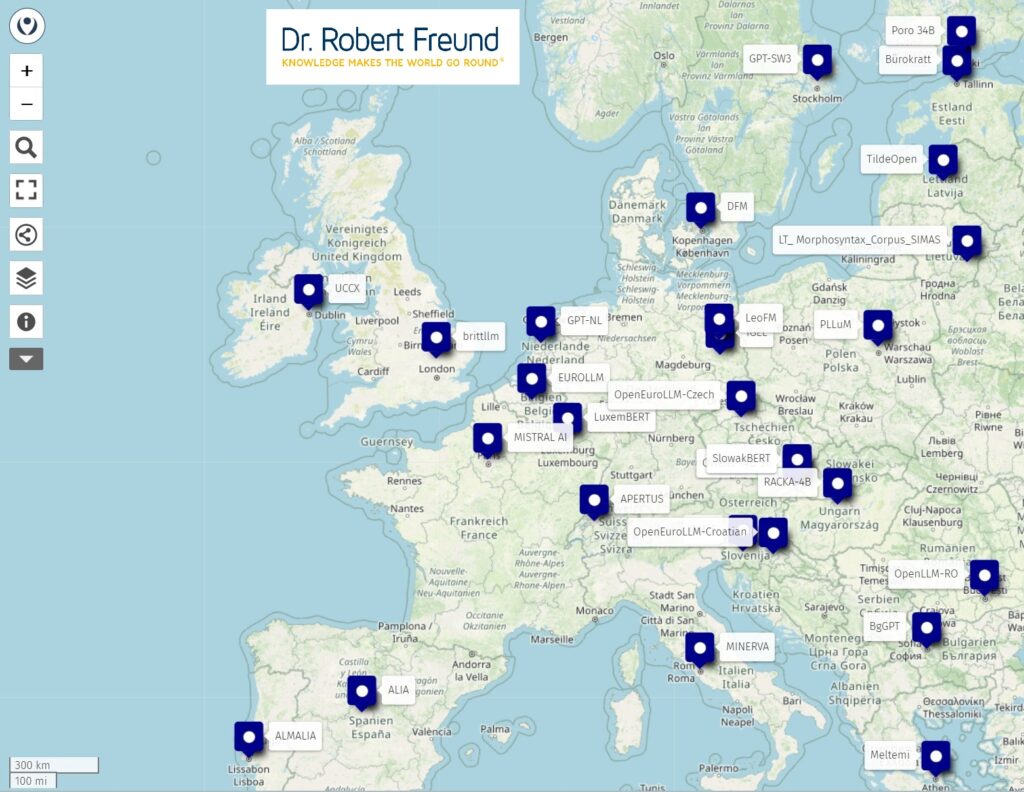
Auf der internationalen Konferenz MCP 2026 (16.-19.09.2026, Balatonfüred, Ungarn) gehe ich auf diese Zusammenhänge in zwei Paper ein.