Die Nutzung den bekannten KI-Modelle (GenAI) wie ChatGPT, Gemini, Grok, Anthropic, Claude etc ist weit verbreitet. Es ist auch möglich, diese Modelle mit eigenen Daten zu trainieren, doch ist der Großteil dann immer noch zu wenig unternehmensspezifisch. Siehe dazu auch Digitale Souveränität: Europa, USA und China im Vergleich.
Mistral AI ist hier in den letzten Jahren einen eigenen Weg gegangen, indem es als europäische Modell Familie DSGVO-konform ist, und auch als Open Source AI zur Verfügung steht.
Mit dem nun veröffentlichten Mistral Forge können Unternehmen auf Basis der eigenen Daten und Expertise ihr eigenes KI-Modell entwickeln.
From your data to your model
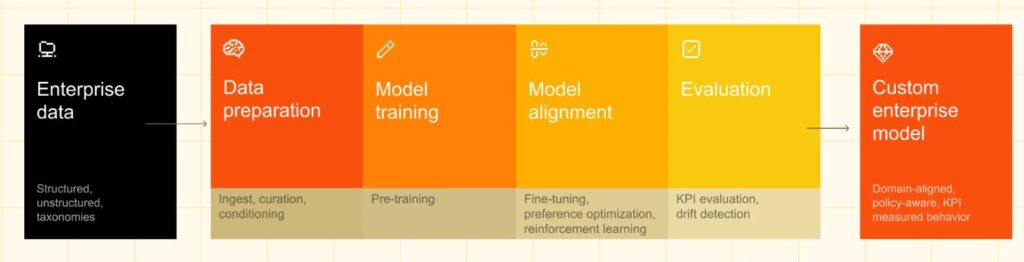
Die einzelnen Schritte werden auf der genannten Webseite ausführlich dargestellt. Es wir spannend zu sehen, welche Organisationen diesen Weg gehen werden. Aktuell sind das immerhin so bekannte Namen wie ASML, Ericsson, ESA und DSO National Laboratories aus Singapur. Siehe dazu auch
Österreichische Verwaltung setzt bei Künstlicher Intelligenz auf Mistral
Mistral Le Chat: Eine europäische Alternative zu ChatGPT
Digitale Souveränität: Mistral 3 KI-Modell-Familie veröffentlicht