Auf den verschiedenen Konferenzen, an denen ich teilgenommen habe, ging es über viele Jahre um Mass Customization and Personalization. Auslöser der Entwicklung war die Veröffentlichung B. Joseph Pine II (1992): Mass Customization. The New Frontier in Business Competition, in der die damals neue hybride Wettbewerbsstrategie vorgestellt wurde.
In der Zwischenzeit gibt es beim Fraunhofer Institut in Stuttgart das Leistungszentrum Mass Personalization. Dort ist man der Auffassung, dass es sich bei Mass Personalization um einen Megatrend handelt
„Mass Personalization ist ein eigenständiges radikal nutzerzentriertes und dennoch nachhaltiges und ressourceneffizientes Konzept, das als Toolbox oder plattformtechnologische Anwendung in der Produktion von morgen fungieren kann“ (Krieg/Groß/Bauernhansl (2024) (Hrsg.): Einstieg in die Mass Personalization. Perspektiven für Entscheider).
Mass Customization ist hier zeitpunktbezogen, und Mass Personalization eher Zeitdauer bezogen zu interpretieren. Beides, Mass Customization und Mass Personalization, sind allerdings immer noch aus der Perspektive des Unternehmens gedacht.
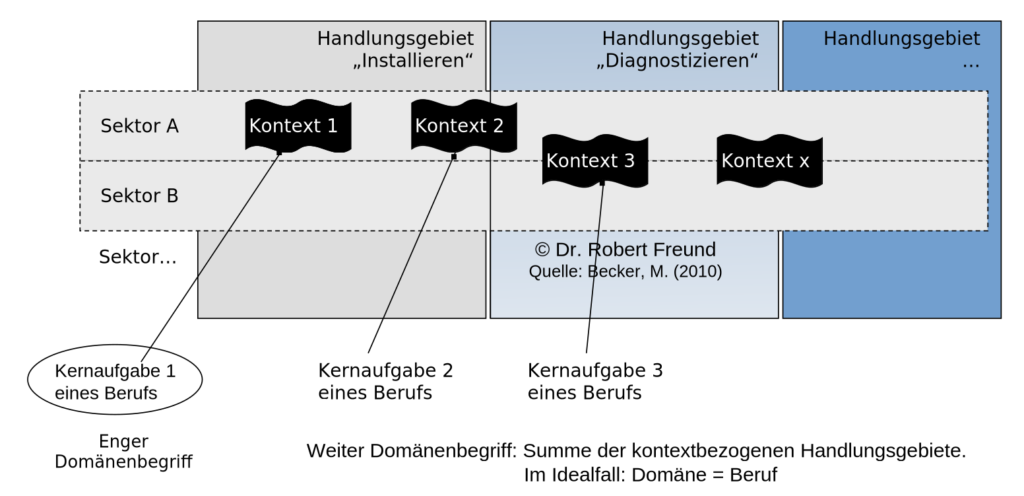
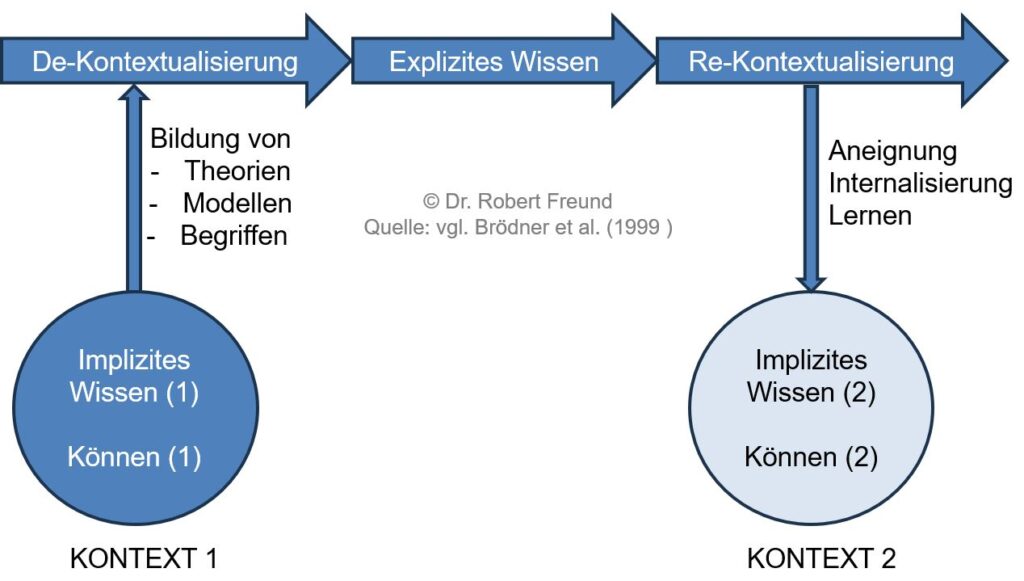
Wenn sich ein Unternehmen auf jeden einzelnen Nutzer so intensiv einstellen will, benötigt es viele Problem- und möglicherweise auch erste Lösungsinformationen vom Nutzer. Bei komplexen Problemen sind diese Informationen nur sehr schwer zu beschreiben (Kontext, Implizites Wissen, Expertise), und schwer vom Nutzer zum Unternehmen übertragbar (Sticky Information, Träges Wissen).
Der Nutzer weiß oft am besten, was er für sein Problem benötigt. Es fehlt oft noch der Schritt zur ersten Umsetzung von eigenen Lösungen. Dieser war in der Vergangenheit sehr aufwendig (Zeit, Geld), sodass die Umsetzung oft von Unternehmen übernommen wurde.
In der Zwischenzeit gibt es durch die Möglichkeiten der Künstlichen Intelligenz, des 3D-Drucks (Additive Manufacturing), oder auch der Robotik und der Open Source Community viele Möglichkeiten, das Produkt selbst zu entwickeln und im Idealfall selbst oder in einer Community herzustellen. Siehe Eric von Hippel (2016): Free Innovation (Open Access).

Eric von Hippel hat dazu schon sehr viele Studien veröffentlich, aus denen hervorgeht, dass der Anteil dieser Open User Innovation in den letzten Jahrzehnten stark angewachsen ist. Diese Innovationen findet man nicht in den offiziellen Statistiken zu Innovationen, denn Innovationen werden dort von Unternehmen entwickelt und auf den Markt gebracht. Was versteht nun von Hippel unter Open User Innovation?
„An innovation is ´open´ in our terminology when all information related to the innovation is a public good—nonrivalrous and nonexcludable”(Baldwin and von Hippel 2011:1400).
”… involves contributors who share the work of generating a design and also reveal the outputs from their individual and collective design efforts openly for anyone to use“ (Baldwin and von Hippel 2011:1403).
Wir wissen alle, dass die Unternehmen nur die Innovationen auf den Markt bringen, die eine entsprechende Rendite versprechen – alles andere bleibt liegen… Doch genau darin liegt die Chance von Open User Innovation: Jeder einzelne kann nicht nur kreativ, sondern auch innovativ sein (Ideen umsetzen) und seine Innovationen anderen (auch kostenlos) zur Verfügung stellen.
Sie meinen das gibt es nicht? Dann schauen Sie sich einmal die vielen Plattformen zu Open Source Software, oder die Plattform Patient Innovation an – Sie werden staunen.
Wenn Sie sich zu diesen Themen informieren wollen: Die MCP Community of Europe trifft sich auf der Konferenz zu Mass Customization and Personalization – MCP 2026 – vom 16.-19.09.2026 in Balatonfüred, Ungarn. Wir sind dabei.