Meine Veröffentlichungen sind zum größten Teil auch auf ResearchGate zu finden. Darunter sind eigene Paper/Chapter und auch gemeinsame Veröffentlichungen mit Kollegen. Im Vergleich zum Januar 2023 haben sich die „reads“ bis zum Januar 2026 auf 19.803 erhöht – ein sattes Plus von 4.777.
Die Anzahl der „reads“ auf Researchgate schwankt je nach Thema und Autor sehr stark, sodass ein Vergleich schwierig ist. Dennoch kann ich – zusammen mit den Co-Autoren – sagen, dass 900 reads für das angegebene Paper bemerkenswert viel ist. Es freut uns, dass an dem Thema wohl Interesse besteht. Thanks to my colleagues and co-authors!
Zwei neue Paper stelle ich auf der MCP 2026, vom 16.-19.2026 in Balatonfüred, Ungarn, vor:
Digital Sovereignty and Open-Source AI: A European Way for Innovative SMEs
Open-Source AI for Open User Innovation: Designing a Personalized Framework
Im April fand in Rom eine Konferenz für Henry Chesbrough statt, um das Werk des Forschers zu seinem 70. Geburtstag zu ehren. Chesbrough hat mit seinem Ansatz eines eher offenen Innovationsprozesses (Open Innovation) in Organisationen, und auch in Forschungsbereichen viel bewirkt.
Enge Mitstreiter haben sich daher in Rom zusammengefunden, auch um Paper zum Thema und zur Person vorzustellen, die in den nächsten Monaten veröffentlicht werden sollen.
Ich bin sehr auf die verschiedenen Veröffentlichungen gespannt, denn ich habe den Weg von Henry Chesbrough in den letzten Jahren intensiv verfolgt.
Beispielsweise habe ich Henry Chesbrough schon auf dem MCPC 2011: 6th Worldcongress on Mass Customization, Personalization and Co-Creation, UC Berkeley, San Francisco, USA (Blogbeitrag) live erlebt.
Es war auch für mich inspirierend zu sehen, wie die Öffnung des Innovationsprozesses (Open Innovation) in Organisationen entwickelt werden kann, und was es für die Organisationen und für deren Kunden bedeutet. In der Zwischenzeit gibt es in allen Bereichen Beispiele für die den erfolgreichen Einsatz von Open Innovation – auch in Zeiten Künstlicher Intelligenz.
In einem meiner beiden Paper, die für die MCP 2026, 16.-19.09.2026, Balatonfüred, Ungarn angenommen wurde, gehe ich auch auf Open Innovation ein. Allerdings betrachte ich hier eher die Perspektive von Eric von Hippel, der Open User Innovation favorisiert.
Wenn man sich die vielen Meldungen in den Medien ansieht, kann man zu dem Schluss kommen, dass es (fast) allen um Aufmerksamkeit, und damit auch um Beeinflussung geht. Dahinter können wirtschaftliche, politische oder soziale Interessen stecken. Viele gehen dabei sehr subtil vor, indem sie Daten nicht genau wiedergeben, oder bewusst aus dem Zusammenhang nehmen.
Oft fehlt bei den Angaben auch die genaue Quelle. Es wird von einer diffusen Studie gesprochen oder geschrieben, doch wird die Quelle nicht genannt. Weiterhin steht bei Zeitungsartikel oft der Hinweis, dass der Beitrag auf Basis von Inhalten anderer Medien geschrieben wurde – diese werden allerdings im Text – wenn überhaupt – nicht deutlich kenntlich gemacht.
Die wenigen Beispiele zeigen schon auf, dass eine mehr wissenschaftlich basierte Arbeit wünschenswert wäre. Die Prinzipien einer solchen Arbeit würden helfen, zwischen eigener Meinung und Quelle zu unterscheiden, um sich ein eigenes Bild machen zu können. Damit kommen wir zur Akademischen Integrität, die es ermöglichen soll, dass wissenschaftlich korrekt und damit transparent gearbeitet und veröffentlicht wird. Gerade in Zeiten von Künstlicher Intelligenz muss das ganz besonders beachtet werden.
Was ist unter Akademischer Integrität zu verstehen?
Dazu habe ich eine Definition der International Centre for Academic Integrity [ICAI] gefunden, die eher im amerikanischen Umfeld genutzt wird. In Europa beziehen sich akademische Institutionen eher auf die Definition der ENAI:
The definition from the European Network for Academic Integrity [ENAI] (2022) is less philosophical than ICAI’s. ENAI states that academic integrity is: Compliance with ethical and professional principles, standards, practices and consistent system of values, that serves as guidance for making decisions and taking actions in education, research and scholarship.“ (Gallant, T. B. ; Davis, M. Khan, Z. R. (2026): ACADEMIC INTEGRITY IN THE AGE OF AI. DOI 10.1017/9781009672078).
Wenn wir unterstellen, dass akademische Integrität bedeutet, selbst verantwortlich, transparent und ethisch zu arbeiten wird klar, dass sich diese Vorgehensweise dann auch auf die Gesellschaft auswirkt.
Es wird Zeit, dass alle Akteure in einer von Künstlicher Intelligenz getriebenen Welt, akademische Prinzipien berücksichtigen. In Europa haben wir erste Ansätze dazu, die oftmals platt mit Regulierung gleichgesetzt werden. In den USA oder China erodieren diese Grundlagen eher. Es ist daher gut, dass wir in Europa einen eigenen Weg gehen, bei dem die Gesellschaft im Mittelpunkt steht.
Sogar in unseren Blogbeiträgen haben wir von Anfang an darauf geachtet, zwischen Originaltexten mit Quellenangaben, und unserer eigenen Meinung zu unterscheiden. Dass ich die Prinzipien bei meiner Dissertation und bei meinen verschiedenen wissenschaftlichen Paper einhalte, versteht sich von selbst. Aktuell beispielsweise für die beiden Paper, die ich für die MCP 2026, 16.-19.09.2026, in Balatonfüred, Ungarn vorbereite.
Zur MCP 2026 Conference zu Mass Customization and Personalization findet vom 16.-19.09.2026 in Balatonfüred, Ungarn, statt. Auch zu dieser Konferenz habe ich Abstracts eingereicht, die in der Zwischenzeit bestätigt wurden.
It is our pleasure to inform you that your abstracts entitled:
Open-Source AI for Open User Innovation: Designing a Personalized Framework
Digital Sovereignty and Open-Source AI: A European Path for Innovative SMEs
were positively reviewed by MCP 2026 Scientific Committee and accepted to proceed to the next stage of uploading full paper according to the template.
Nun geht es daran, das Paper bis zum 31. Mai 2026 nach den Konferenzvorgaben fertigzustellen.
Wenn alles klappt, werden ich beide Paper im September auf der Konferenz vorstellen, und mit den Kollegen diskutieren.
Conceptual technology illustration of artificial intelligence. Abstract futuristic background
In meinen Konferenz-Paper der letzten Jahrzehnte habe ich natürlich immer darauf geachtet, die jeweilige Quelle anzugeben. Damit ist aus wissenschaftlicher Sicht gewährleistet, dass deutlich wird, was von einem anderen Autor, und was von mir stammt.
Mit der gleichen Vorgehensweise erstellen wir auch unsere Blogbeiträge. Da wir dafür keinen KI-generierten Content nutzen, kann der Leser darauf vertrauen. Das ist besonders wichtig, daVertrauen die Basis für die Arbeit mit Künstlicher Intelligenzist – it all starts with trust.
Sollte also jemand Künstliche Intelligenz für seine Blogbeiträge, oder sogar für seine wissenschaftlichen Veröffentlichungen nutzen, steht er vor mehreren Herausforderungen, denn das jeweils verwendete KI-Modell zeigt nicht immer auf, welche Quelle es verwendet hat.
Texte, die originalgetreu von anderen übernommen wurden, werden zwar bei einigen KI-Modellen gekennzeichnet, doch andere Texte sind möglicherweise von der KI selbst zusammengestellt worden. Earp et al. (2025) haben das in einem veröffentlichten Paper als Herkunftsproblem (provenance problem) bezeichnet:
„Suppose the LLM trained on, but does not mention, Smith’s text. And suppose we have never read it or even heard of Smith or her work. So, we don’t cite the paper either. Still, our essay now inherits — via nebulous, machine-mediated means — a distinctive insight that Smith developed but for which she receives no credit“
Source: Earp, B.D., Yuan, H., Koplin, J. et al. LLM use in scholarly writing poses a provenance problem. Nat Mach Intell 7, 1889–1890 (2025). https://doi.org/10.1038/s42256-025-01159-8.
Es handelt sich dabei also nicht um Plagiate, sondern um eine subtilere Art der Verschleierung der Herkunft.
Im wissenschaftlichen Kontext wird das thematisiert, doch wie sieht es mit der privaten Nutzung der allseits eingesetzten KI-Modelle wie ChatGPT, Gemini, Anthropix, Grok etc. aus, die man als Black Box bezeichnen kann?
Da deren Trainingsdaten nicht transparent sind, ist das Herkunftsproblem natürlich auch hier vorhanden, doch die einzelnen Nutzer reflektieren über die Ergebnisse nicht so, wie es Wissenschaftler tun, die auf Qualität achten.
Dadurch werden alle möglichen und unmöglichen KI-Resultate weitergegeben und sind dann wiederum Bestandteil der nächsten Ergebnisse. In dem gesamten System entsteht so eine Unschärfe, die auch zu Manipulationen genutzt werden kann.
Immer mehr Menschen nutzen Künstliche Intelligenz, um gesundheitliche oder psychologische Themen zu analysieren. Der Ratgeber ist dann also nicht der Arzt oder der Psychologe, sondern ChatGPT oder andere bekannte KI-Modelle.
Bei der Kommunikation Mensch – KI dringt die KI immer tiefer in das Profil des Menschen ein. Die Profile werden dann auch dazu genutzt, dem Nutzer zu schmeicheln.
Schmeicheln bedeutet „jemandem übertrieben und nicht ganz aufrichtig Angenehmes sagen, um dessen Gunst zu gewinnen“ (Quelle).
In einer Studie (Jain et al. 2026) wurden zwei Schmeicheleien unterschieden: (1) Zustimmungsschmeichelei (agreement sycophancy) – die Tendenz von Modellen, übermäßig positive Reaktionen hervorzurufen, und (2) Perspektivenschmeichelei (perspective sycophancy) – das Ausmaß, in dem Modelle die Sichtweise eines Nutzers widerspiegeln.
Es stellte sich daher die Frage: Verstärkt Personalisierung das Ausmaß der Schmeicheleien?
„Our results raise the question of whether some personalization approaches may amplify sycophancy. Prior work often attributes sycophancy to preference alignment, since users prefer responses that are affirmative or aligned with their perspective. Yet in aligned models, we find that user memory profiles are associated with further increases in agreement sycophancy, and that contexts providing more information about the user drive perspective sycophancy“ Source: Jain et al. (2026): Interaction Context Often Increases Sycophancy in LLM | PDF
Es wurde also in der Studie klar, dass Nutzerprofile eher Zustimmungsschmeicheleien, und Kontextinformationen eher Perspektivenschmeichelei verstärken. Egal welches Element man also betrachtet, Schmeicheleien verstärken sich wohl mit der Zeit.
Bei diesen Entwicklungen stehen wir noch am Anfang, doch deutet sich schon jetzt ein entsprechender Klärungsbedarf an: Wie können Personalisierung und Schmeicheleien ausbalanciert werden? Siehe dazu auch
Meine Veröffentlichungen sind zum größten Teil auch auf ResearchGate zu finden. Darunter sind eigene Paper/Chapter und auch gemeinsame Veröffentlichungen mit Kollegen.
Thanks to my colleagues and co-authors!
Im Vergleich zum Januar 2023 haben sich die „reads“ bis zum Januar 2026 auf 19.803 erhöht – ein sattes Plus von 4.777.
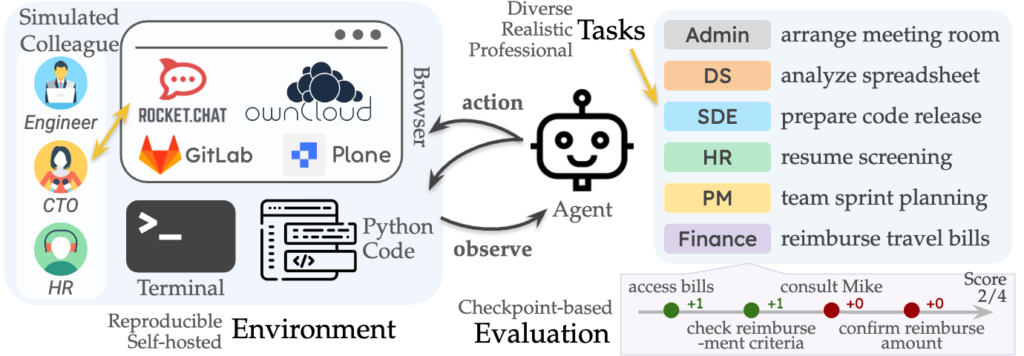
Es ist mehr als eine interessante Spielerei von KI-Enthusiasten: KI-Agenten (AI-Agents) können immer mehr Aufgaben in einem Unternehmen autonom übernehmen. Um das genauer zu untersuchen, haben Wissenschaftler in dem Paper
wichtige Grundlagen dargestellt, und auch untersucht, welche Tasks in einem Unternehmen von KI-Agenten autonom übernommen werden können.
Wie in der Abbildung zu erkennen ist, wurden Mitarbeiterrollen simuliert (Engineer, CTO, HR) und verschiedene Tasks angenommen. Bei dem Admin beispielsweise „arrange meeting room“ und bei dem Projektmanager (PM) „teams sprint planning“, was auf das Scrum Framework hinweist. Als Modelle für Trainingsdaten wurden Large Language Models (LLMs) genutzt – closed source und open weight models:
„We test baseline agents powered by both closed API-based and open-weights language models (LMs), and find that the most competitive agent can complete 30% of tasks autonomously“ (Xu et al (2025).
Es wird zwar ausdrücklich auf die Beschränkungen (Limitations) hingewiesen, doch gibt diese Untersuchung konkrete Hinweise darauf, welche Aufgaben (Tasks) in Zukunft möglicherweise von KI-Agenten in Unternehmen übernommen werden können.
Interessant bei dem Paper ist, dass dazu auch eine ausführliche Website https://the-agent-company.com/ aufgebaut wurde, auf der Videos, inkl. der verschiedenen KI-Agenten zu finden sind. Interessiert Sie das? Wenn ja, nutzen Sie einfach den Quick Start Guide und legen Sie los!
Natürlich sollte jedes Unternehmen für sich herausfinden, welche Tasks von KI-Agenten sinnvoll übernommen werden sollten. Dabei wird schon deutlich, dass es hier nicht darum geht, ganze Berufe zu ersetzen, sondern ein Sammelsurium von unterschiedlichen Tasks (Ausgaben) autonom durchführen zu lassen.
Hervorzuheben ist aus meiner Sicht natürlich, dass die Autoren mit dem letzten Satz in ihrem Paper darauf hinweisen, dass die Nutzung von Open Source AI in Zukunft ein sehr vielversprechender Ansatz sein kann – aus meiner Sicht: sein wird!
„We hope that TheAgentCompany provides a first step, but not the only step, towards these goals, and that we or others may build upon the open source release of TheAgentCompany to further expand in these promising directions“ (Xu et al 2025).
Über die immer intensivere Vernetzung von Menschen, Dingen, Organisationen und Gesellschaften ist eine Komplexität entstanden, die es zu bewältigen gilt. Ein Ansatz, die entstandene Komplexität in Projekten zu bewältigen ist, iterativ/agil vorzugehen.
Darüber hinaus habe ich natürlich auch noch nach einer wissenschaftlichen Begründung gesucht, die ich möglicherweise in dem Paper von Hao Dong et al. (2024) gefunden habe.
„According to the Project Management Institute (PMI, 2023), “A project is a series of structured tasks, activities, and deliverables that are carefully executed to achieve a desired outcome,” and “Each aspect of a project must go through the phases of the project life cycle before reaching an end goal. This life cycle allows project managers to execute each phase of their project effectively. It enables them to plan each task and activity meticulously, ensuring the highest chances of a project’s success.” Therefore, Agile Project Management requires “a systematic approach” to apply its flexibility (Augner & Schermuly, 2023) and productivity (Hofman et al., 2023). The misalignment between project management and the Agile Manifesto now coexists with the widespread adoption of agile in project management (Dong et al., 2022). The fragmented body of literature and confusion in practice call for further investigation and examination. (…) Nonetheless, since agile is explicitly a software development approach, many of the values and principles from the Agile Manifesto cannot be directly applied to non-software projects“ (Hao Dong et al. (2024)).
Auf Basis der Projektdefinition des Project Management Instituts (PMI) zeigen die Autoren auf, dass Agiles Projektmanagement ein systematisches Vorgehen erfordert, was wiederum eine Diskrepanz zum Agilen Manifest darstellt. Das ist für viele doch eine überraschende Erkenntnis, da bisher davon ausgegangen wurde, dass wir von Agilem Projektmanagement sprechen, wenn es auf der Basis des Agilen Manifests durchgeführt wird. Es ist daher sehr gut, dass die Autoren die angesprochene Diskrepanz weiter untersucht haben. In einem der nächsten Blogbeiträge werde ich darauf eingehen.
Solche Zusammenhänge thematisieren wir auch in den von uns entwickelten Blended Learning Lehrgängen Projektmanager/in (IHK) und Projektmanager/in AGIL (IHK). Informationen dazu, und zu aktuellen Terminen, finden Sie auf unserer Lernplattform.
Die Entgrenzung (Siehe dazu Entgrenzungsdimensionen im Arbeitsprozess) macht auch vor Innovationen nicht Halt. Der früher eher geschlossene Innovationsprozess (Closed Innovation) in Organisationen wird mehr oder weniger geöffnet, sodass vielfältige Optionen von Co-Creation entstehen. Henry Chesbrough hat den Begriff Open Innovation bekannt gemacht – allerdings immer in Bezug auf Unternehmen/Organisationen. Das Paper Bertello, A., De Bernardi, P. & Ricciardi, F. Open innovation: status quo and quo vadis – an analysis of a research field. Rev Manag Sci (2023) erhebt den Anspruch, den Status Quo von Open Innovation zu beschreiben und auch einen Ausblick auf zukünftige Entwicklungen zu geben. Teile davon werden auch ausführlich mit Quellenangaben erreicht. Warum nur Teile?
Es gibt neben der Betrachtung von Henry Chesbrough auch noch einen anderen Blick auf Open Innovation, und zwar ist es die Perspektive von Eric von Hippel. Siehe dazu ausführlich Eric von Hippel (2017). Free Innovation oder auch Eric von Hippel (2005): Democratizing Innovation. Dieser Ansatz kommt in dem oben genannten Paper allerdings nur sehr kurz vor.
„Although open and user innovation have different fathers (i.e., Chesbrough and von Hippel, respectively), theoretical underpinnings, and assumptions, they both reject the traditional idea that innovation must be created and commercialized within a single organization (Piller and West 2014)“ (ebd.).
Wenn man bei Eric von Hippel in der akademischen Welt eher von User Innovation spricht, und dabei den Begriff Open Innovation immer nur mit Henry Chesbrough in Verbindung bringt, wird es meines Erachtens dem Kerngedanken Eric von Hippels nicht gerecht, denn Eric von Hippel möchte alle möglichen Grenzen von Innovationen demokratisieren und somit Innovationen, und Innovationsprozesse, öffnen. Open Innovation ist so verstanden eher ein Bottom-Up-Ansatz, der nicht zwingend Unternehmen/Organisationen erfordert. Das macht den Ansatz für viele nicht so attraktiv, da viele Universitäten gerne mit Unternehmen zusammenarbeiten – Honi soit qui mal y pense. Siehe dazu auch Innovationsmanagement.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.