Legende
(CEN TS 16555-2014):
1 Sammeln von Informationen
2 Erzeugen von Lösungen
3 Rasches Lernen
4 Bewertung
5 Synthese und Outputs
6 Ergebnisse
Unternehmen setzen für ihren Innovationsprozess Künstliche Intelligenz ein. Auf der individuellen Ebene ist das natürlich auch möglich. Beispielsweise kann Künstliche Intelligenz das eigene innovative Denken unterstützen. Die Abbildung zeigt dazu die insgesamt sechs Schritte – vom Sammeln von Informationen (1) bis zu den Ergebnissen (6).
In jedem einzelnen Schritt sollten Sie überlegen, ob Sie nur ein KI-Modell verwenden wollen, oder ob es nicht besser ist, spezielle KI-Modelle zu nutzen. Siehe dazu auch KI-Modelle: Von „One Size Fits All“ über Variantenvielfalt in die Komplexitätsfalle?
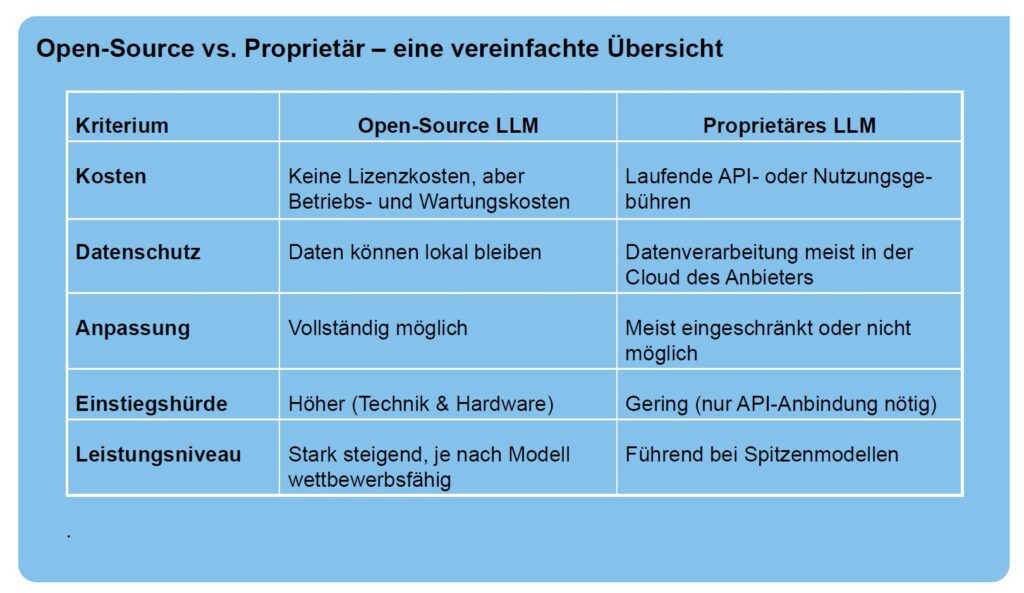
Weiterhin sollten Sie sich überlegen, ob Sie die bekannten proprietären KI-Modelle für ihre innovativen Ideen nutzen wollen. Denken Sie bitte daran, dass diese wenig transparent sind und Sie nicht genau wissen, was mit ihren Ideen passiert. Siehe dazu auch Das Kontinuum zwischen Closed Source AI und Open Source AI.
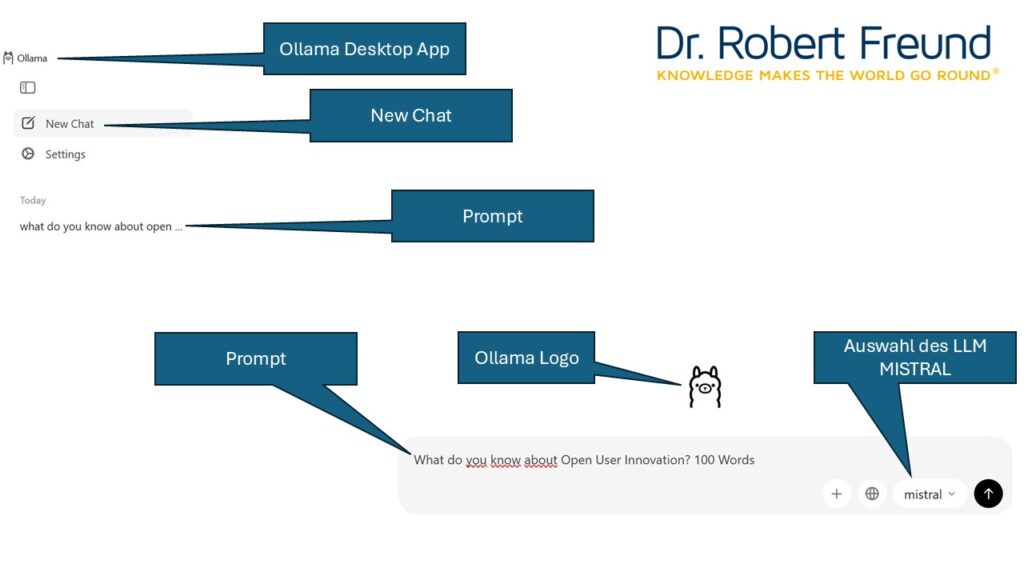
Unser Vorschlag ist daher, dass Sie zur Unterstützung ihres innovativen Denkens, in jedem Schritt Open Source KI-Modelle nutzen. Dass kann MISTRAL LE CHAT als Alternative zu ChatGPT etc, ein Modell wie Mistral AI für alle Schritte, oder auch ein Konzept mit unterschiedlichen Modellen sein, die Sie auf Huggingface finden können.
Natürlich ist es auch möglich, für die oben genannten Schritte einen, oder mehrere KI-Agenten zu nutzen – natürlich möglichst auch Open Source basiert.
Überlegen Sie abschließend noch, ob Sie alles auf ihrem Laptop, oder auf einem eignen Server laufen lassen können. Damit hätten Sie die Kontrolle über ihre Ideen.
„Erst ignorieren sie dich, dann lachen sie über dich, dann bekämpfen sie dich, dann hast du gewonnen“ Mahatma Gandhi.
Sie können dann immer noch selbst entscheiden, ob Sie Ihre Ergebnisse mit anderen teilen, oder diese sogar Unternehmen anbieten wollen.
Alles im Sinne einer eigenen Digitalen Souveränität.